Czy to już doping ?
Indeksy zazwyczaj przyspieszają wyszukiwanie wierszy w tabelach.
Indeksy funkcyjne pozwalają skorzystać nawet podczas stosowania różnych operacji w zapytaniach.
Indeks jest strukturą drzewiastą, można więc szybko znaleźć położenie poszukiwanych wierszy. Konsekwencja będzie dużo szybsze wyszukiwanie niż analizowanie wierszy krok po kroku.
Tworzę testową tabelkę TEST_USERS
———————————————-
CREATE TABLE test_users (
id_users NUMBER(10) NOT NULL,
first_name VARCHAR2(40) NOT NULL,
last_name VARCHAR2(40) NOT NULL,
sex VARCHAR2(1),
date_reg DATE
);
Pętla kursorem się toczy
Popełniam więc krótki skrypt który uzupełni przykładową tabelkę wirtualnymi danymi inspirując się zawodnikami ‘Kuchennej rewolucji’:
———————————
BEGIN
FOR CUR_REC IN 1 .. 5000 LOOP
IF MOD(CUR_REC, 2) = 0 THEN
INSERT INTO test_users
VALUES
(CUR_REC, 'Rafał’ || CUR_REC, 'Majka’, 'M’, SYSDATE);
ELSE
INSERT INTO test_users
VALUES
(CUR_REC, 'Peter’ || CUR_REC, 'Sagan’, 'F’, SYSDATE);
END IF;
COMMIT;
END LOOP;
END;
/
Ufaj ale sprawdzaj 😉
Dla pewności sprawdzam czy tabelka została wypełniona
SELECT * FROM test_users;
Za mało, za dużo, Statystyka
Warto w tym momencie przeliczyć również statystyki na naszej tabeli.
EXEC DBMS_STATS.gather_table_stats(USER, 'test_users’, cascade => TRUE);
Inwigilacja, czyli włączam podsłuch i słucham
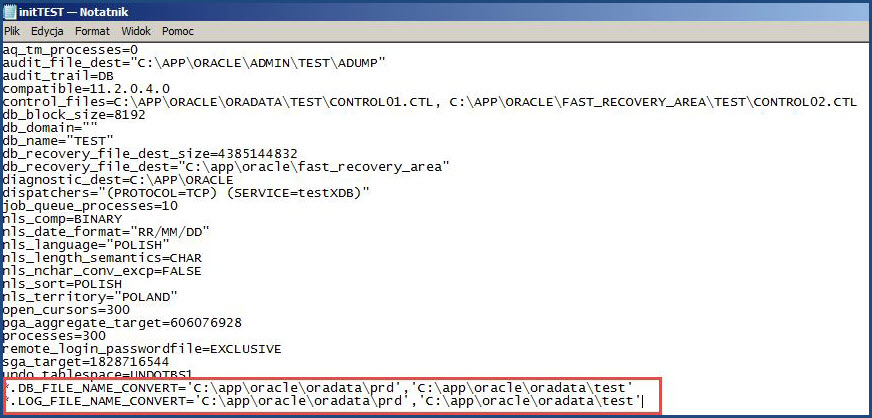
Włączam autotrace i sprawdzam plan zapytania (pamiętając że tabela nie ma żadnych indeksów)
SET AUTOTRACE ON
SELECT * FROM TEST_USERS WHERE UPPER(FIRST_NAME) = 'RAFAŁ2′;
Zgodnie z przewidywaniami jest przeglądana cała tabela w poszukiwaniu jednego wiersza.
Bez analizy i przygotowania się nie da
Dla testów stworzę zwykły, najprostszy indeks na tabeli, po czym znów przeliczę statystki.
CREATE INDEX ind_first_name ON test_users (first_name);
EXEC DBMS_STATS.gather_table_stats(USER, 'test_users’, cascade => TRUE);
Test zwykłego indeksu
SET AUTOTRACE ON
SELECT * FROM TEST_USERS WHERE UPPER(FIRST_NAME) = 'RAFAŁ2′;
niestety indeks na nic nam się zdał. Baza i tak przeglądała całą tabelę w poszukiwaniu jednego wiersza.
Zadanie dla inżyniera – konstruktora
Skoro używam w warunku zapytania podniesienia do wielkich liter i wiem ze takie zapytanie będzie wykonywane często to tworzę indeks funkcyjny dzięki któremu Oracle przestanie przeglądać całą tabelę w poszukiwaniu wiersza.
DROP INDEX ind_first_name;
CREATE INDEX ind_first_name ON test_users (UPPER(first_name));
Test prawdy
SET AUTOTRACE ON
SELECT * FROM TEST_USERS WHERE UPPER(FIRST_NAME) = 'RAFAŁ2′;
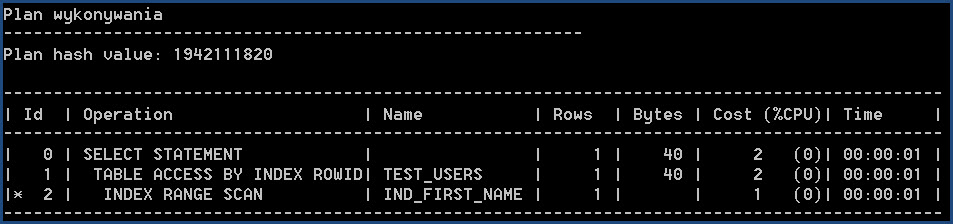
Analiza kosztów J
W sumie nie potrzeba żadnego specjalistycznego sprzętu do analizy wyników. Widać że Oracle korzysta już z indeksu funkcyjnego i koszt zajmuje to 40 bajtów zamiast 1500 oraz koszt procesora 2 zamiast 9.
Mniejsze znaczy szybsze J